
Mission
Why care about predictive analytics while artificial intelligence is the real next big thing?
Discussions are often narrowed down to the flavors of deep learning or reinforcement learning and feel like senseless technical competitions. Let’s take a business perspective.
PredictiveWorks. refers to Gartner’s Analytic Continuum and considers predictive analytics an agile business method, backed by a well-defined business process, to continuously answer the following questions:
- What happened?
- Why did it happen?
- What will happen?
- How can we make it happen?
Too less bleeding-edge? Why do many enterprise AI projects still fail when they try to build a business solution to answer these simple questions?
The game is not to bring yet another "patent-pending" algorithm onto the market and fight a fight which neural networks are better than others. While companies are still in trouble to integrate their cloud data silos and prepare for analytics.
The game gets lost in many areas. Algorithms are definitely a minor problem. They are good enough to answer the overwhelming part of predictive business questions.
The real game is to rethink predictive analytics from ground up to get this method business ready for enterprises at any scale.
Standardization
Nowadays many excellent open source big data analytics & computing libraries exist, but each with a certain technology lens on the data spectrum. Answering predictive questions most often requires to operate many of them in a skill-extensive and time-consuming process, with human experts in the loop to stick pieces individually together.
Standardization and unification is considered a first-class citizen to achieve the mission goal.
Many different technologies have been extensively evaluated and the winner is a combination of two open-source solutions, Apache Spark, and Google CDAP of former Cask Inc.
Apache Spark
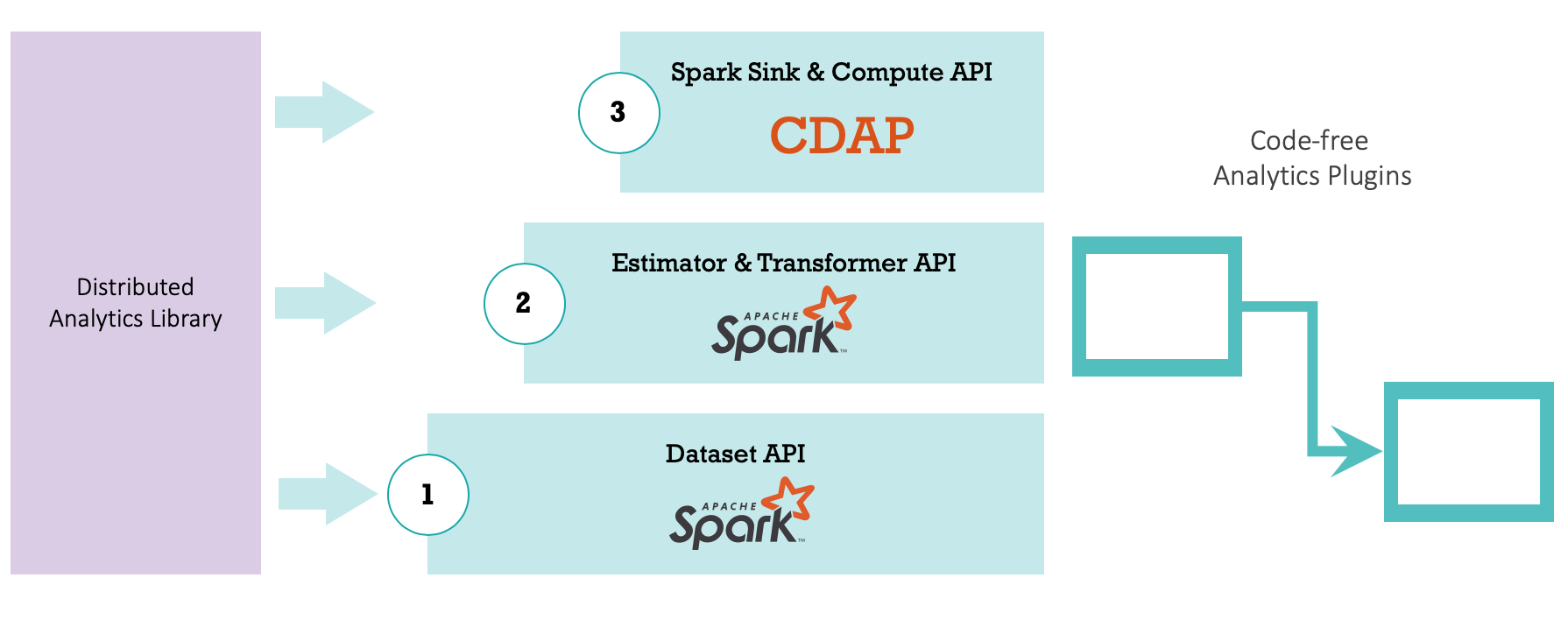
Apache Spark is a distributed in-memory data computation framework and transformed into todays framework of choice for enterprises with a need to process data at scale.
Apache Spark offers technical APIs of Estimators and Transformers and represents a solid foundation for standardization and unification of programmatic data computation tasks. each
Google CDAP
Google CDAP is a data application platform designed to accelerate the implementation of data pipelines or workflows.
Google CDAP offers a standardized Plugin API to implement pipelines and its components or stages. Different stages benefit from the same interface and can be seamlessly sticked together to build complex data processing pipelines.
While Apache Spark can be used to standardize the content of a processing stage, Google CDAP is best to standardize and unify how different stages work together.
The team of PredictiveWorks. combines Apache Spark and Google CDAP in a best-of-breed standardization process to transform existing distributed analytics libraries, written either in Java or Scala into standardized pipeline stages (or plugins).
Plug & Play Analytics
PredictiveWorks. plug-and-play analytics represents the result of leveraging the specified standardization process to turn a variety of popular analytics libraries, from deep learning, machine learning, time series and text analysis to sql query and business rule execution, into a set of code-free pipeline plugins.
Business users can organize and orchestrate plugins as data pipelines leveraging a graphical point-and-click interface without the need of programming skills.
PredictiveWorks. ships with the following plug-and-play packages:
Train as You Predict
Focusing on how to organize and build advanced analytics pipelines in the most simplest way, is an important step to achieve the specified mission goal. But it is by far not enough to turn predictive analytics into sustainable competitive advantage.
Data scientists often develop data models very fast. Bringing trained models into production is hampered by different infrastructures and technologies. This runs the risk that models produce small or no effect for corporate data processing.
Instead of aiming to standardize the format of data models outputted by a wide variety of data science libraries (see MLFlow), PredictiveWorks. abstracts from the libraries itself and standardizes them as code-free pipeline plugins.
The advantage of this approach is that the same standardized technology can be used for model building and usage in production.
Context Aware Pipelines
Data pipelines are technical solutions to retrieve automated insights and foresights. They implement a certain business case, organized in tasks, and are often related to other pipelines. Data pipelines, separated from this context are senseless, and managing hundreds or even thousands of them without context is impossible.
PredictiveWorks. ships with the concept of business templates. Templates aggregate pipelines, plugins and business context in a single structured information asset and define what companies do with their data and why.
Pipeline Knowledge
Business templates define the DNA of modern data-driven companies and represent a huge treasure of business knowledge. Without a powerful pipeline knowledge management most of this knowledge cannot be reused for similar business cases.
User acceptance and experience is key to any corporate knowledge management and decides whether the wheel is reinvented or not. PredictiveWorks. ships with the world’s first pipeline knowledge management system that is organized as a market place and turns knowledge discovery into a shopping experience.